mirror of
https://github.com/Colin-XKL/Colinx-Blog.git
synced 2026-01-11 02:01:29 +08:00
chore: lint text and auto correct
This commit is contained in:
committed by
 GitHub
GitHub
parent
3aba40b4de
commit
3e3fb03791
@@ -1,7 +1,7 @@
|
||||
---
|
||||
title: 2023 静态网站托管服务速度对比
|
||||
date: 2022-12-25
|
||||
description: 对几家喜闻乐见的静态网站托管服务商 Vercel、Netlify、Cloudflare Pages、Azure Static Pages 测个速, 2023 版
|
||||
description: 对几家喜闻乐见的静态网站托管服务商 Vercel、Netlify、Cloudflare Pages、Azure Static Pages 测个速,2023 版
|
||||
categories:
|
||||
- 技术
|
||||
tags:
|
||||
|
||||
@@ -32,7 +32,7 @@ Huginn 使用多个不同功能的 Agent 组合搭配来实现一系列功能,
|
||||
|
||||
该元素可以用 CSS 选择器`.meiwen`选择到。
|
||||
|
||||
**Tips:** class=xxx则使用`.xxx`,如果为id=xxx则使用`#xxx`
|
||||
**Tips:** class=xxx 则使用`.xxx`,如果为 id=xxx 则使用`#xxx`
|
||||
|
||||
该标签是 a 标签,我们可以继续限定一下条件,使用`a.meiwen`
|
||||
|
||||
@@ -249,7 +249,7 @@ Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like
|
||||
}
|
||||
```
|
||||
|
||||
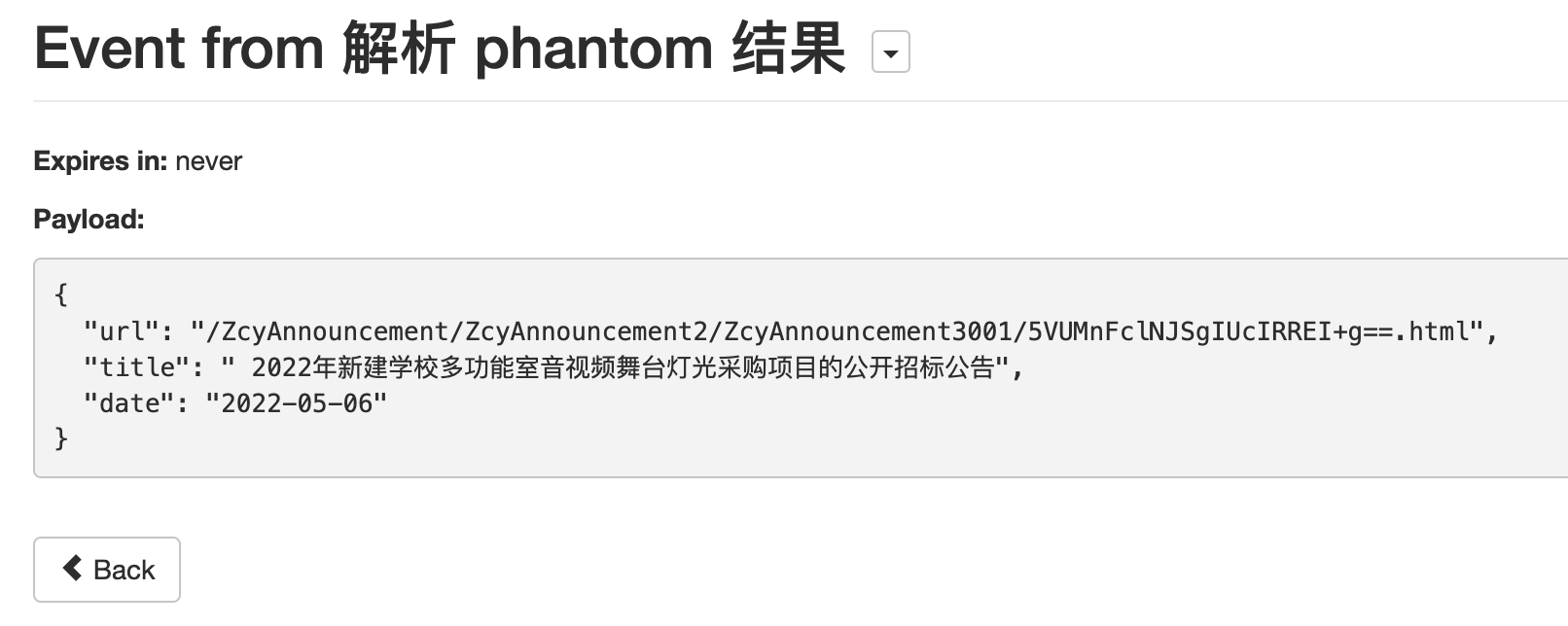
注意将原来的`url:??`的部分更改为`"url_from_event": "{{url}}"`,这样就指定使用Phantom JS Cloud为我们获取的完整网页,接下来的操作就大同小异了。配置好要爬取的字段和规则后点击Dry Run就可以看到结果
|
||||
注意将原来的`url:??`的部分更改为`"url_from_event": "{{url}}"`,这样就指定使用 Phantom JS Cloud 为我们获取的完整网页,接下来的操作就大同小异了。配置好要爬取的字段和规则后点击 Dry Run 就可以看到结果
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -185,7 +185,7 @@ python3 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
|
||||
}
|
||||
```
|
||||
|
||||
update 20230720: 部分镜像源不再可用, 更新镜像源配置. 参考 https://gist.github.com/y0ngb1n/7e8f16af3242c7815e7ca2f0833d3ea6
|
||||
update 20230720: 部分镜像源不再可用,更新镜像源配置。参考 https://gist.github.com/y0ngb1n/7e8f16af3242c7815e7ca2f0833d3ea6
|
||||
|
||||
配置完成后`sudo systemctl restart docker`重启 docker 服务,然后输入`sudo docker info`,在输出结果的末尾可以看到`Registry Mirrors`里会出现我们刚刚配置的 Docker Hub 镜像
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
---
|
||||
title: 个人向 Linux 新服务器初始化清单
|
||||
date: 2023-03-14
|
||||
description: 一份 Linux 初始化清单, 避免每次拿到新的服务器都要一个个去各种地方搜集指令, 以做备忘 & 供有需要的朋友参考. 以目前最新的 Debian 11 Bullseye 为例
|
||||
description: 一份 Linux 初始化清单,避免每次拿到新的服务器都要一个个去各种地方搜集指令,以做备忘 & 供有需要的朋友参考。以目前最新的 Debian 11 Bullseye 为例
|
||||
categories:
|
||||
- 技术
|
||||
tags:
|
||||
@@ -61,7 +61,7 @@ sudo sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.
|
||||
|
||||
CentOS 系建议启用 EPEL, PowerTools 等 repo 以更方便地安装常用软件和工具。此处不再赘述
|
||||
|
||||
推荐的几个国内镜像站: [清华大学 TUNA 镜像站](https://mirrors.tuna.tsinghua.edu.cn/), [中科大 USTC LUG 镜像站](https://mirrors.ustc.edu.cn/), [腾讯镜像站](https://mirrors.cloud.tencent.com/)
|
||||
推荐的几个国内镜像站:[清华大学 TUNA 镜像站](https://mirrors.tuna.tsinghua.edu.cn/), [中科大 USTC LUG 镜像站](https://mirrors.ustc.edu.cn/), [腾讯镜像站](https://mirrors.cloud.tencent.com/)
|
||||
|
||||
#### 基础软件
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
---
|
||||
title: 关于双语字幕这件小事
|
||||
date: 2023-09-10
|
||||
description: 今天这篇文章来探讨下双语字幕这件小事. 首先对于一部外语影片或剧集, 原生的英文字幕肯定是能够轻松获得的, 但是匹配、高质量的翻译字幕缺并不总是能找到. 这里分享一些我在寻找和手动 DIY 双语字幕的一些经验和想法, 我自己也编写了一些工具, 有同样需求的朋友也可以快速上手:D
|
||||
description: 今天这篇文章来探讨下双语字幕这件小事。首先对于一部外语影片或剧集,原生的英文字幕肯定是能够轻松获得的,但是匹配、高质量的翻译字幕缺并不总是能找到。这里分享一些我在寻找和手动 DIY 双语字幕的一些经验和想法,我自己也编写了一些工具,有同样需求的朋友也可以快速上手:D
|
||||
categories:
|
||||
- 杂记
|
||||
- 技术
|
||||
@@ -13,13 +13,13 @@ tags:
|
||||
|
||||
|
||||
|
||||
今天这篇文章来探讨下双语字幕这件小事.
|
||||
今天这篇文章来探讨下双语字幕这件小事。
|
||||
|
||||
首先对于一部外语影片或剧集, 原生的英文字幕肯定是能够轻松获得的, 但是匹配、高质量的翻译字幕缺并不总是能找到. 这里分享一些我在寻找和手动 DIY 双语字幕的一些经验和想法, 我自己也编写了一些工具, 有同样需求的朋友也可以快速上手:D
|
||||
首先对于一部外语影片或剧集,原生的英文字幕肯定是能够轻松获得的,但是匹配、高质量的翻译字幕缺并不总是能找到。这里分享一些我在寻找和手动 DIY 双语字幕的一些经验和想法,我自己也编写了一些工具,有同样需求的朋友也可以快速上手:D
|
||||
|
||||
## 1. 考虑寻找现成的高质量字幕
|
||||
|
||||
很多大火的剧集都会有字幕组第一时间跟进字幕制作和资源的发布, 我们可以在各种 BT, PT 站点找到这些字幕组打包好的自带字幕的资源, 或者也可以在第三方的字幕站点上寻找合适的字幕.
|
||||
很多大火的剧集都会有字幕组第一时间跟进字幕制作和资源的发布,我们可以在各种 BT, PT 站点找到这些字幕组打包好的自带字幕的资源,或者也可以在第三方的字幕站点上寻找合适的字幕。
|
||||
|
||||
这里安利一个油猴脚本:[豆瓣资源下载大师](https://greasyfork.org/zh-CN/scripts/329484-%E8%B1%86%E7%93%A3%E8%B5%84%E6%BA%90%E4%B8%8B%E8%BD%BD%E5%A4%A7%E5%B8%88-1%E7%A7%92%E6%90%9E%E5%AE%9A%E8%B1%86%E7%93%A3%E7%94%B5%E5%BD%B1-%E9%9F%B3%E4%B9%90-%E5%9B%BE%E4%B9%A6%E4%B8%8B%E8%BD%BD),可以在豆瓣的影视详情页右侧显示有资源的站点,非常方便
|
||||
|
||||
@@ -28,37 +28,37 @@ tags:
|
||||
|
||||

|
||||
|
||||
中文字幕推荐 [字幕库](http://zimuku.org/), 大部分字幕都可以在这里找到. 其他语言可以到 [OpentSubtitles](https://www.opensubtitles.org/zh) 碰碰运气, 虽然界面有点古朴, 但是人家资源还是很丰富滴
|
||||
中文字幕推荐 [字幕库](http://zimuku.org/), 大部分字幕都可以在这里找到。其他语言可以到 [OpentSubtitles](https://www.opensubtitles.org/zh) 碰碰运气,虽然界面有点古朴,但是人家资源还是很丰富滴
|
||||
|
||||
## 2. 字幕的时间轴修正
|
||||
|
||||
对于下载的字幕, 我们常遇到的问题就是时间轴不匹配, 相信每个影视爱好者都或多或少碰到过这样的问题. 产生不匹配有多种原因, 典型的比如:
|
||||
对于下载的字幕,我们常遇到的问题就是时间轴不匹配,相信每个影视爱好者都或多或少碰到过这样的问题。产生不匹配有多种原因,典型的比如:
|
||||
|
||||
- 视频帧率不匹配
|
||||
- 视频有删减(片头或者片中都有可能, 常见于电视剧集, 有些中间有广告转场有些没有)
|
||||
- 视频版本不一样(各种删减版, 完整版, 导演剪辑版等等)
|
||||
- 视频有删减 (片头或者片中都有可能,常见于电视剧集,有些中间有广告转场有些没有)
|
||||
- 视频版本不一样 (各种删减版,完整版,导演剪辑版等等)
|
||||
|
||||
最后一种差异的地方太多, 建议重新找字幕. 对于前面两种情况, 文本的部分没有太多差异, 只需要调整字幕的时间轴就可以了.
|
||||
最后一种差异的地方太多,建议重新找字幕。对于前面两种情况,文本的部分没有太多差异,只需要调整字幕的时间轴就可以了。
|
||||
|
||||
这里需要一些对齐时间轴的工具, 这个市面上已经有很多了, 大部分都是基于将对白音频持续时间和字幕对白持续时间做匹配, 然后进行字幕整体时间轴的缩放或平移来实现对齐的.
|
||||
这里需要一些对齐时间轴的工具,这个市面上已经有很多了,大部分都是基于将对白音频持续时间和字幕对白持续时间做匹配,然后进行字幕整体时间轴的缩放或平移来实现对齐的。
|
||||
|
||||
比如 [Sushi](https://github.com/tp7/Sushi), 以及[ffsubsync](https://github.com/smacke/ffsubsync)
|
||||
|
||||
还有一类是最近比较火的, 利用 AI 来对语音进行识别, 输出对应的字幕. 一半都是通过 Whisper 这个开源的语音识别模型来实现的, 比如[autosubsync](https://github.com/oseiskar/autosubsync).
|
||||
还有一类是最近比较火的,利用 AI 来对语音进行识别,输出对应的字幕。一半都是通过 Whisper 这个开源的语音识别模型来实现的,比如[autosubsync](https://github.com/oseiskar/autosubsync).
|
||||
|
||||
这类语音识别的 AI 目前已经很成熟了, 市面上有很多商业应用, 比如办公软件 飞书, 腾讯会议一般都会支持会议语音转文字. 但是这种都是为会议场景准备的. 其实国内网易有道在这块做的更早, 对英文支持更好, [网易见外](https://jianwai.youdao.com/)可以直接对音频进行识别, 并生成 srt 文件, 甚至还可以直接加上翻译, 效率直接拉满. 免费额度基本够用, 各位轻度使用的朋友不要错过.
|
||||
这类语音识别的 AI 目前已经很成熟了,市面上有很多商业应用,比如办公软件 飞书,腾讯会议一般都会支持会议语音转文字。但是这种都是为会议场景准备的。其实国内网易有道在这块做的更早,对英文支持更好,[网易见外](https://jianwai.youdao.com/)可以直接对音频进行识别,并生成 srt 文件,甚至还可以直接加上翻译,效率直接拉满。免费额度基本够用,各位轻度使用的朋友不要错过。
|
||||
|
||||
当然, 这类 AI 语音识别和翻译现阶段还是差了点意思, 在各种影视作品中, 各类人名, 专有名词, 还有各种各样的梗(比如 The Simpsons ), AI 处理起来还是有点够呛, 所以最好还是优先选择人工调教后的字幕比较好.
|
||||
当然,这类 AI 语音识别和翻译现阶段还是差了点意思,在各种影视作品中,各类人名,专有名词,还有各种各样的梗 (比如 The Simpsons ), AI 处理起来还是有点够呛,所以最好还是优先选择人工调教后的字幕比较好。
|
||||
|
||||
上面罗列的那些对齐工具只能处理字幕和影片都是原生语言的情况, 比如处理英文电影的英文字幕, 但是对于要对时间轴不匹配的中英文双语字幕就基本没辙了. 找遍了全网都没找到合适的工具, 所以我就自己写了一个 [srt-fuzzy-sync](https://github.com/Colin-XKL/srt-fuzzy-sync)
|
||||
上面罗列的那些对齐工具只能处理字幕和影片都是原生语言的情况,比如处理英文电影的英文字幕,但是对于要对时间轴不匹配的中英文双语字幕就基本没辙了。找遍了全网都没找到合适的工具,所以我就自己写了一个 [srt-fuzzy-sync](https://github.com/Colin-XKL/srt-fuzzy-sync)
|
||||
|
||||
> fuzzy-sync 是一个简单的同步 srt 字幕的工具, 通过指定一个与音轨匹配的参考字幕文件, 来将另一个未同步的字幕进行匹配, 时间轴修正, 使得其可以与音轨正确对齐.
|
||||
> fuzzy-sync 是一个简单的同步 srt 字幕的工具,通过指定一个与音轨匹配的参考字幕文件,来将另一个未同步的字幕进行匹配,时间轴修正,使得其可以与音轨正确对齐。
|
||||
|
||||
简单点来说呢, 这是一个专门用来对双语字幕时间轴进行修正的工具. 你手头有一个英文电影资源, 一个正确对齐的英文字幕, 一个没对齐的双语字幕, 这个时候你就可以用 srt-fuzzy-sync 这个工具, 将英文字幕设定为参考, 然后对双语字幕的时间轴进行修正, 就可以得到一个时间轴正确的双语字幕啦!
|
||||
简单点来说呢,这是一个专门用来对双语字幕时间轴进行修正的工具。你手头有一个英文电影资源,一个正确对齐的英文字幕,一个没对齐的双语字幕,这个时候你就可以用 srt-fuzzy-sync 这个工具,将英文字幕设定为参考,然后对双语字幕的时间轴进行修正,就可以得到一个时间轴正确的双语字幕啦!
|
||||
|
||||
为什么叫 fuzzy-sync 呢, 这主要是为了通用性, 只对两个字幕之间高度相同的一些关键对白进行匹配, 其他的对白则只是基于匹配结果进行整体偏移, 这样做的好处是即便你找的这两个字幕的对白数量不一样, 仍然可以完成同步.
|
||||
为什么叫 fuzzy-sync 呢,这主要是为了通用性,只对两个字幕之间高度相同的一些关键对白进行匹配,其他的对白则只是基于匹配结果进行整体偏移,这样做的好处是即便你找的这两个字幕的对白数量不一样,仍然可以完成同步。
|
||||
|
||||
一般英文的 SDH 无障碍字幕里都会有很多非对白场景下的文字提示, 比如
|
||||
一般英文的 SDH 无障碍字幕里都会有很多非对白场景下的文字提示,比如
|
||||
|
||||
> (Theme Music Playing)
|
||||
|
||||
@@ -66,23 +66,23 @@ tags:
|
||||
|
||||
> (Bird Singing)
|
||||
|
||||
而影片对应中文字幕里一般都不会加上这些翻译. 此外中文字幕还常常对影片中出现的标题、店铺招牌、标语、新闻标题做翻译说明, 种种因素导致中英文字幕在句子的数量上不是严格对等的.
|
||||
而影片对应中文字幕里一般都不会加上这些翻译。此外中文字幕还常常对影片中出现的标题、店铺招牌、标语、新闻标题做翻译说明,种种因素导致中英文字幕在句子的数量上不是严格对等的。
|
||||
|
||||
此外这些字幕出现的时间, 通常是没有对应的对白音频的. 上面基于音频匹配的都无法很好地处理这类情况, 所以我才抛弃按句匹配的方法, 改为按一些句子很长, 具有标志性, 在影片中通常只会出现一次的关键语句匹配.
|
||||
此外这些字幕出现的时间,通常是没有对应的对白音频的。上面基于音频匹配的都无法很好地处理这类情况,所以我才抛弃按句匹配的方法,改为按一些句子很长,具有标志性,在影片中通常只会出现一次的关键语句匹配。
|
||||
|
||||
至于找不到的现成双语字幕的, 那就需要我们自己动手制作啦.
|
||||
至于找不到的现成双语字幕的,那就需要我们自己动手制作啦。
|
||||
|
||||
## 3. 自制双语字幕
|
||||
|
||||
有时只能找到现成的中文字幕和原版英文字幕, 但是没有双语的版本, 这个时候就需要我们手动合并了.
|
||||
有时只能找到现成的中文字幕和原版英文字幕,但是没有双语的版本,这个时候就需要我们手动合并了。
|
||||
|
||||
这里推荐一个工具网站 [Subtitle Tools](https://subtitletools.com/merge-subtitles-online), 里面有各种简单的字幕工具, 比如字幕合并, 字幕格式转换.
|
||||
这里推荐一个工具网站 [Subtitle Tools](https://subtitletools.com/merge-subtitles-online), 里面有各种简单的字幕工具,比如字幕合并,字幕格式转换。
|
||||
|
||||
对于手上又对齐的英文字幕和对齐的英文字幕, 但是数量很多不想一个个到网站上去合并的, 可以考虑 srt-merge 这个工具. 不过原作者很久没更新了, 我这里也编写了一个工具, 也可以实现一样的功能. [dual-lang-sub-tool](https://github.com/Colin-XKL/dual-lang-sub-tool/tree/main)
|
||||
对于手上又对齐的英文字幕和对齐的英文字幕,但是数量很多不想一个个到网站上去合并的,可以考虑 srt-merge 这个工具。不过原作者很久没更新了,我这里也编写了一个工具,也可以实现一样的功能。[dual-lang-sub-tool](https://github.com/Colin-XKL/dual-lang-sub-tool/tree/main)
|
||||
|
||||
此外还有一种常见的情况, 就是我们下载的 WebRip 版本资源, 影片已经内置了多国语言分别的字幕, 这些资源大部分是来源于 Netfilx, Disney Plus , iTunes 这些, 我们可以直接提取影片资源内置的两种语言的字幕然后将它们合并.
|
||||
此外还有一种常见的情况,就是我们下载的 WebRip 版本资源,影片已经内置了多国语言分别的字幕,这些资源大部分是来源于 Netfilx, Disney Plus , iTunes 这些,我们可以直接提取影片资源内置的两种语言的字幕然后将它们合并。
|
||||
|
||||
内置字幕的提取可以使用 ffmpeg 工具, 首先用 ffmpeg -i 文件路径 来查看基本信息, 确定好字幕所在的 track, 比如 Stream #0:3(chi) Subtitle, 这种就是说明 3 号 stream 是中文字幕.
|
||||
内置字幕的提取可以使用 ffmpeg 工具,首先用 ffmpeg -i 文件路径 来查看基本信息,确定好字幕所在的 track, 比如 Stream #0:3(chi) Subtitle, 这种就是说明 3 号 stream 是中文字幕。
|
||||
|
||||
```shell
|
||||
# example output # ......
|
||||
@@ -105,10 +105,10 @@ Metadata: title : big5
|
||||
ffmpeg -i xxx.mkv -map 0:3 -c:s srt output.srt
|
||||
```
|
||||
|
||||
提取完成后就可以直接合并得到成品的双语字幕了, 但是你应该也会觉得这样提取太麻烦, 尤其是一部剧几十集的情况. 一般同一个资源, 里面各个音轨和字幕的排布是一样的, 比如上面只取了一集进行查看, 其他集数都是一样的, 中文字幕都是在 stream 0:3, shell 循环一下就可以了.
|
||||
提取完成后就可以直接合并得到成品的双语字幕了,但是你应该也会觉得这样提取太麻烦,尤其是一部剧几十集的情况。一般同一个资源,里面各个音轨和字幕的排布是一样的,比如上面只取了一集进行查看,其他集数都是一样的,中文字幕都是在 stream 0:3, shell 循环一下就可以了。
|
||||
|
||||
当然你可能觉得这还是太麻烦了, 我也是这么想的, 所以 dual-lang-srt-tool 工具也支持自动检测, 导出, 合并双语字幕啦:D DIY 双语字幕可以很简单
|
||||
当然你可能觉得这还是太麻烦了,我也是这么想的,所以 dual-lang-srt-tool 工具也支持自动检测,导出,合并双语字幕啦:D DIY 双语字幕可以很简单
|
||||
|
||||
## 后记
|
||||
|
||||
对于一些专有名词太多, AI 翻译质量欠佳, 又没有现成中文字幕可供参考的, 那目前就没有很好的办法了. 通常我遇到这种情况是用 AI 的版本将就下, 或者直接全英文一把梭. 不过随着 AI 技术的发展, 后面或许可以考虑将过往季的字幕喂给 AI 让 ta 自己学习人名地名翻译, 再辅以各种新闻八卦材料让 AI 也能对各种潮流热梗烂熟于心, 到那个时候制作双语字幕就是分分种的事情了, 可以预见的是这样的 AI 应该有生之年就可以用上, 至于是好事还是坏事, 那就交给未来去评判吧.
|
||||
对于一些专有名词太多,AI 翻译质量欠佳,又没有现成中文字幕可供参考的,那目前就没有很好的办法了。通常我遇到这种情况是用 AI 的版本将就下,或者直接全英文一把梭。不过随着 AI 技术的发展,后面或许可以考虑将过往季的字幕喂给 AI 让 ta 自己学习人名地名翻译,再辅以各种新闻八卦材料让 AI 也能对各种潮流热梗烂熟于心,到那个时候制作双语字幕就是分分种的事情了,可以预见的是这样的 AI 应该有生之年就可以用上,至于是好事还是坏事,那就交给未来去评判吧。
|
||||
|
||||
@@ -40,7 +40,7 @@ TLDR:当前的 AI 工具尚且不足以完成整部中文网文小说作品,
|
||||
|
||||
这次的封面图的底图就是采用 AI 绘制的,坦白说一开始我个人不是特别满意,不是我预期想象中的样子。但是对于这整个过程使用的时间来说,我觉得这个效率反而是最惊人的。一分钟不到,符合基本设定要求的底图生成好了。我再画三分钟添加个文字,摆一摆位置,一个基本元素完备,风格色彩合格的网文小说封面图就制作好了。相比较之下,听闻之前的类似出图都是以天级别计算的,费用甚至几百上千,这其中的效率差简直恐怖。
|
||||
|
||||
我之前也尝试过手动搭建 stable diffusion 在自己的 GPU 服务器上运行,用的 gradio 那个 web ui,自我感觉良好,出图的效果也挺不错。但是拿给非工科的朋友用,上来就是吐槽界面怎么全是英文,怎么那么多按钮,该怎么启动,该怎么写提示词,怎么不会画中国风。有一说一,那个时候的 AI 工具更像是一个工程原型机,而现在被稿定设计这样的 toC 平台引进做好本土化适配和产品化设计之后,使用上手出乎意料的简单。
|
||||
我之前也尝试过手动搭建 stable diffusion 在自己的 GPU 服务器上运行,用的 gradio 那个 web ui,自我感觉良好,出图的效果也挺不错。但是拿给非工科的朋友用,上来就是吐槽界面怎么全是英文,怎么那么多按钮,该怎么启动,该怎么写提示词,怎么不会画中国风。有一说一,那个时候的 AI 工具更像是一个工程原型机,而现在被稿定设计这样的 toC 平台引进做好本土化适配和产品化设计之后,使用上手出乎意料的简单。
|
||||
|
||||
**图片超分模型:Upscayl**
|
||||
|
||||
@@ -152,43 +152,43 @@ Claude 和 GPT 说到底还是外国人训练的,对于网文小说这种题
|
||||
|
||||
比如让 GPT 写一段餐馆里众人围着小电视机的日常对白。
|
||||
|
||||
> 街道上行人并不多,都是些步履匆匆的上班族,或悠哉散步的老人。秋阳从树隙间洒落下来,洋洋洒洒铺满了整条街道。路边的建筑不是传统的日式木质结构,而是夹杂着些西式的红砖或水泥房屋,显得格调混杂却又和谐统一。
|
||||
> 街道上行人并不多,都是些步履匆匆的上班族,或悠哉散步的老人。秋阳从树隙间洒落下来,洋洋洒洒铺满了整条街道。路边的建筑不是传统的日式木质结构,而是夹杂着些西式的红砖或水泥房屋,显得格调混杂却又和谐统一。
|
||||
>
|
||||
> 这是一条看似平凡却让人感到亲切温馨的小街道,没有太多喧嚣与烦扰,却处处透着人情味。林凡和明石正要开始一段充满未知冒险的旅程,这家小餐馆像一个温暖的港湾,让疲惫的身心得以喘息。
|
||||
> 这是一条看似平凡却让人感到亲切温馨的小街道,没有太多喧嚣与烦扰,却处处透着人情味。林凡和明石正要开始一段充满未知冒险的旅程,这家小餐馆像一个温暖的港湾,让疲惫的身心得以喘息。
|
||||
>
|
||||
> 两人兴许不知道前方有怎样的险阻在等待,但是此刻,享受这份静谧与温情,已经足够。
|
||||
> 两人兴许不知道前方有怎样的险阻在等待,但是此刻,享受这份静谧与温情,已经足够。
|
||||
>
|
||||
> 小餐馆的电视上,又在播放着新闻。
|
||||
>
|
||||
> “天呐,蔬菜价格又要涨价了!”一个头发花白的老奶奶放下碗筷,双手扶额无奈地说。
|
||||
> “天呐,蔬菜价格又要涨价了!”一个头发花白的老奶奶放下碗筷,双手扶额无奈地说。
|
||||
>
|
||||
> “是呀,最近物价飞涨,生活费用压力太大了。”旁边一位白胡子老头也叹了口气。
|
||||
> “是呀,最近物价飞涨,生活费用压力太大了。”旁边一位白胡子老头也叹了口气。
|
||||
>
|
||||
> “就是有证据显示这起事件有阴谋!”那名中年男子神秘兮兮地小声说。
|
||||
>
|
||||
> “天哪!这也太可怕了。”老奶奶捂住嘴巴,一副震惊的表情。
|
||||
> “天哪!这也太可怕了。”老奶奶捂住嘴巴,一副震惊的表情。
|
||||
>
|
||||
> “唉,真不知道这社会要到什么地步。”老头叹道。
|
||||
> “唉,真不知道这社会要到什么地步。”老头叹道。
|
||||
>
|
||||
> 电视上又切换到了其他新闻,几名上班族模样的青年男女也加入了讨论。
|
||||
> 电视上又切换到了其他新闻,几名上班族模样的青年男女也加入了讨论。
|
||||
>
|
||||
> “诶,你们看,股市又跌了!”一个男生着急地说。
|
||||
> “诶,你们看,股市又跌了!”一个男生着急地说。
|
||||
>
|
||||
> “最近经济形势越来越不景气啊。”一个女生也愁眉苦脸地说。
|
||||
>
|
||||
> “工作这么辛苦,钱还是省不下来,年轻人现在日子没指望了。”另一个男生一脸失望。
|
||||
> “工作这么辛苦,钱还是省不下来,年轻人现在日子没指望了。”另一个男生一脸失望。
|
||||
>
|
||||
> 三名年轻人叹息连连,满脸忧虑之色。这时,电视画面跳转到了娱乐新闻,几名艺人的花边新闻占据了荧屏。
|
||||
> 三名年轻人叹息连连,满脸忧虑之色。这时,电视画面跳转到了娱乐新闻,几名艺人的花边新闻占据了荧屏。
|
||||
>
|
||||
> “来来来,看这个,明星的绯闻啦!”一个女生眼前一亮,话锋一转。
|
||||
> “来来来,看这个,明星的绯闻啦!”一个女生眼前一亮,话锋一转。
|
||||
>
|
||||
> “嗨,这些娱乐新闻才叫有意思。”另一个女生也来了精神。
|
||||
> “嗨,这些娱乐新闻才叫有意思。”另一个女生也来了精神。
|
||||
>
|
||||
> “工作那么辛苦,看点这些解压解压嘛。”一个男生笑着说。
|
||||
> “工作那么辛苦,看点这些解压解压嘛。”一个男生笑着说。
|
||||
>
|
||||
> 三人又投入到了对明星私生活的讨论中,烦恼的表情一扫而空,兴奋地指点着电视画面。
|
||||
> 三人又投入到了对明星私生活的讨论中,烦恼的表情一扫而空,兴奋地指点着电视画面。
|
||||
>
|
||||
> 林凡和明石面面相觑,感慨百态人心,千头万绪,便也没去打扰他们继续闲聊。
|
||||
> 林凡和明石面面相觑,感慨百态人心,千头万绪,便也没去打扰他们继续闲聊。
|
||||
|
||||
还有一些人物对白类的,写起来很麻烦的,也可以让 GPT 代劳水字数。
|
||||
|
||||
@@ -200,24 +200,24 @@ Claude 和 GPT 说到底还是外国人训练的,对于网文小说这种题
|
||||
>
|
||||
> 一位穿着白大褂的科学家拿着一把匕首,匕首微微泛着幽蓝的光芒。
|
||||
>
|
||||
> 不知为什么, 林凡看到这个光芒第一个想起的是明石。
|
||||
> 不知为什么,林凡看到这个光芒第一个想起的是明石。
|
||||
>
|
||||
> 匕首插进了那块金属板。金属板的表面顿时出现了一阵阵波纹,波纹越来越大,最后化作一张人脸出现。
|
||||
>
|
||||
> 林凡看着这张诡异的人脸,心脏不由自主地加速跳动,呼吸急促,额头渗出细汗,双腿忍不住微微发抖。
|
||||
>
|
||||
> "你在害怕什么?你是不是害怕这块金属板上有一张狰狞的人脸?"
|
||||
> "你在害怕什么?你是不是害怕这块金属板上有一张狰狞的人脸?"
|
||||
>
|
||||
> 科学家的声音响起,让林凡清醒了过来。他看着林凡,露出一丝嘲讽的微笑:"害怕什么?你在害怕这块金属板上的人脸是假的?哈哈!你真幼稚啊!"
|
||||
> "你在胡说八道些什么!"林凡怒声反驳,"你们的实验已经失败了,现在我们就能证明它不是真的!"
|
||||
> 科学家的声音响起,让林凡清醒了过来。他看着林凡,露出一丝嘲讽的微笑:"害怕什么?你在害怕这块金属板上的人脸是假的?哈哈!你真幼稚啊!"
|
||||
> "你在胡说八道些什么!"林凡怒声反驳,"你们的实验已经失败了,现在我们就能证明它不是真的!"
|
||||
>
|
||||
> "证明?怎么证明?"科学家冷哼一声,"如果这块金属板上没有人类的话,你认为你有资格跟我们谈条件吗?"
|
||||
> "证明?怎么证明?"科学家冷哼一声,"如果这块金属板上没有人类的话,你认为你有资格跟我们谈条件吗?"
|
||||
>
|
||||
> 林凡愣了愣,一时语塞。这个时候,明石走了过来,"我们已经找到了这个实验的关键,我想我们应该跟他们谈判一下。"
|
||||
>
|
||||
> 他们跟着科学家走到了那个办公室里。那里坐着四个人,分别是两男三女,男人的年纪约摸四十岁左右,看上去有些阴郁,眼睛里透露着一抹狡黠的寒光。女人的年龄比较大,约有七十多岁,头发花白,脸上的皱纹深邃。男人看上去三十多岁,皮肤黝黑,眼眸深邃。三女中有两个看上去年龄稍微小一点的女孩,大约只有十六七岁,但是却穿着一套白大褂,一看就像是医院里的护士装。
|
||||
>
|
||||
> "你们是谁?想干什么?"其中一个男人开口问道。
|
||||
> "你们是谁?想干什么?"其中一个男人开口问道。
|
||||
|
||||
上面这两段文字,前面一段是 Claude 生成的,后面这段时彩云小梦生成的。可以看出有这非常明显的风格差异。
|
||||
|
||||
@@ -226,7 +226,7 @@ Claude 生成的很『正确』,前后通顺合理,但是总感觉没那味
|
||||
彩云小梦生成的相较而言就很『疯癫』,写的一长剧情上就容易出 bug,而且动不动就『冷哼』『嘲讽』,情绪波动倒是有了,不过总感觉全是国内网文的套路化,应该是国内网文看多了吧也怪不得人家的模型 hhh
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
## 关于创作欲
|
||||
|
||||
Reference in New Issue
Block a user