mirror of
https://github.com/Colin-XKL/Colinx-Blog.git
synced 2026-03-08 05:01:27 +08:00
Merge pull request #41 from Colin-XKL/update-img-url
Update imgs' CDN URL
This commit is contained in:
@@ -26,7 +26,7 @@ Huginn使用多个不同功能的Agent组合搭配来实现一系列功能,一
|
||||
|
||||
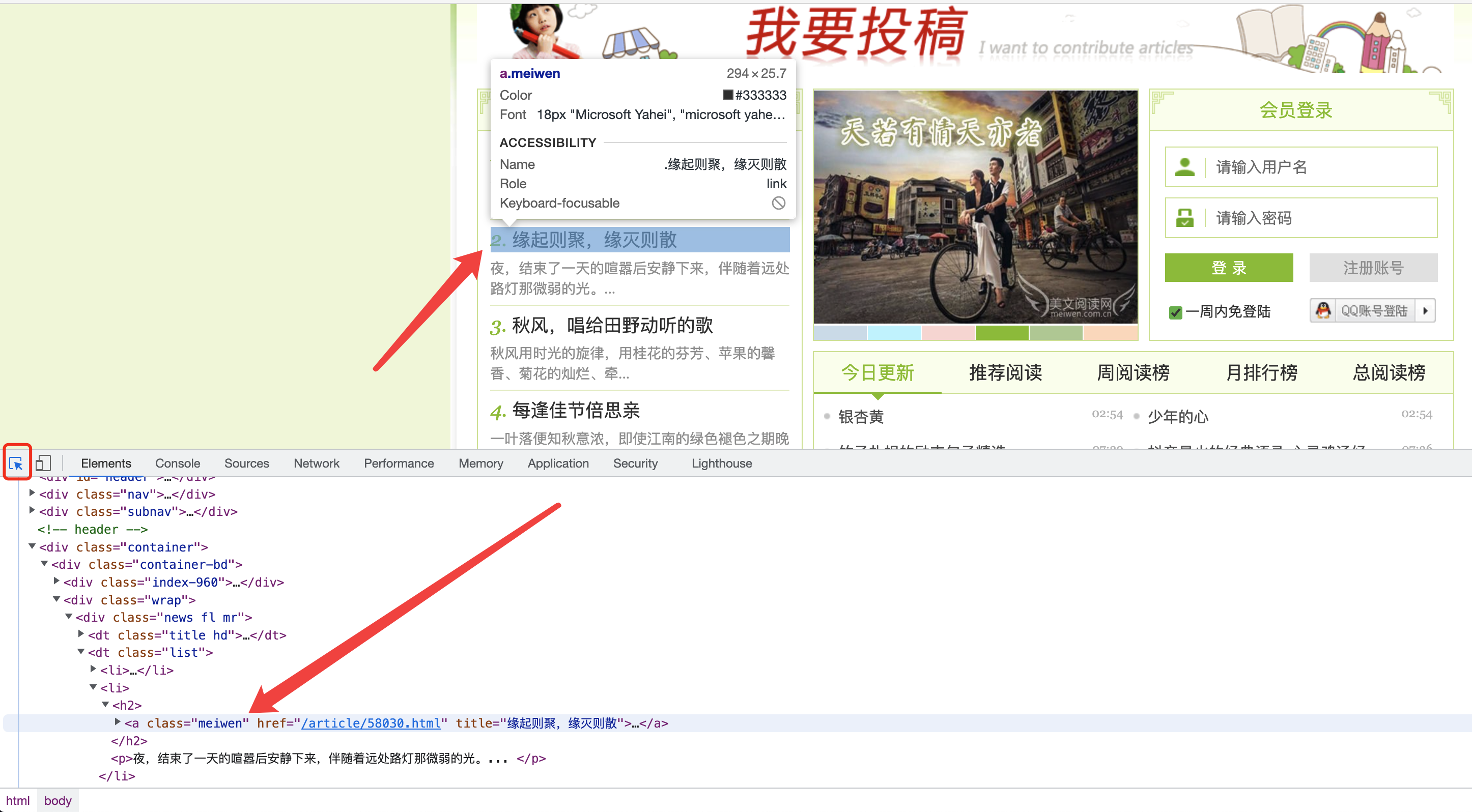
右键网页打开开发者工具,屏幕会分出一部分空间显示开发者工具窗口,点击左上角的按钮再把鼠标移动到页面上可以选择页面的某一个元素,比如这里我们要爬取推荐文章列表,推荐文章列表的每一项都有同样的样式,我们可以使用CSS选择器来指定爬取该项
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -44,7 +44,7 @@ Huginn使用多个不同功能的Agent组合搭配来实现一系列功能,一
|
||||
|
||||
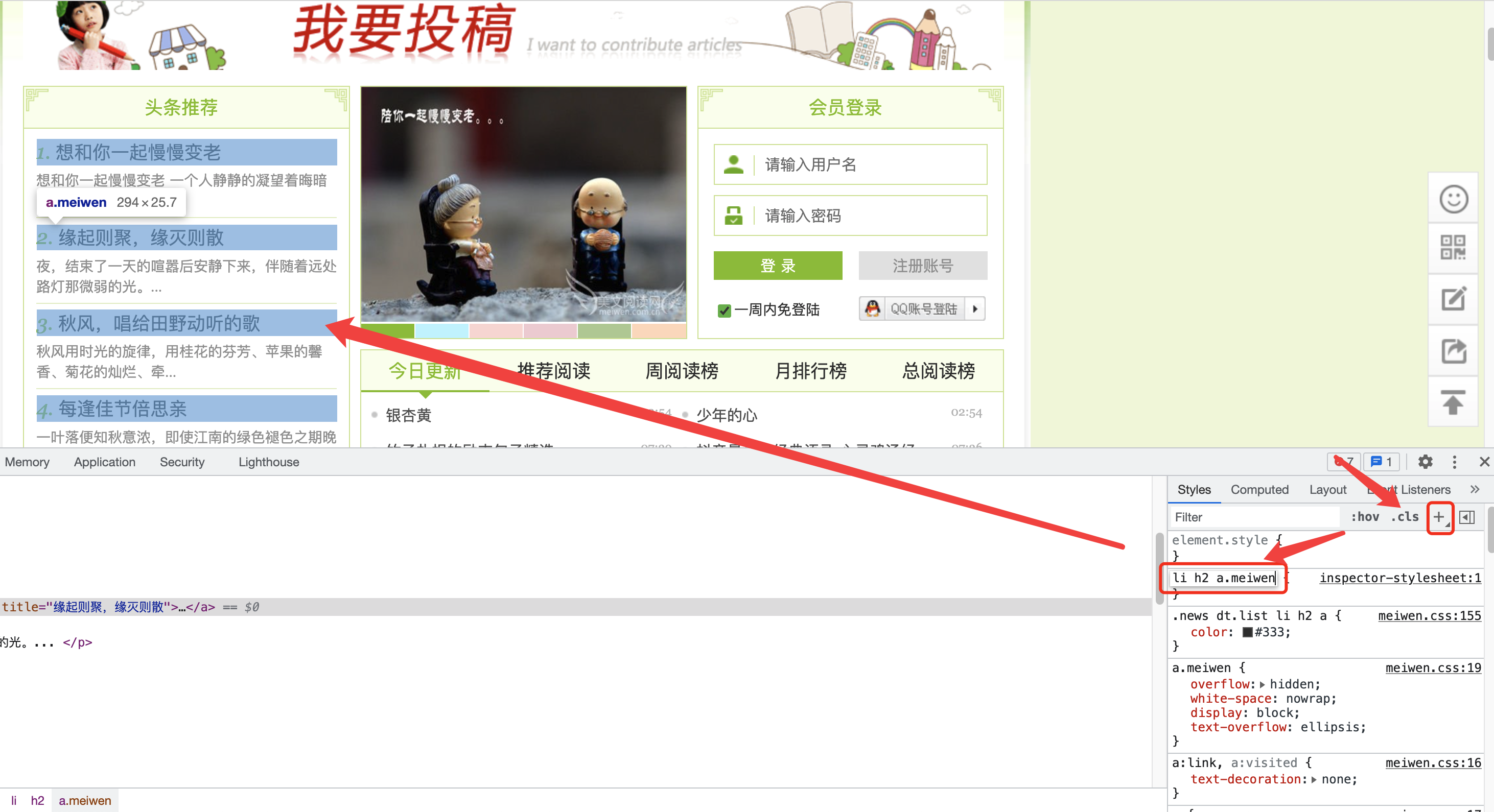
你也可以在右侧Style面板里点击加号添加一个自定义样式,输入CSS选择器,浏览器会自动高亮符合条件的网页元素,你可以使用这个功能来检验你写的CSS选择器是否正确以及是不是提取的你想要的内容
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -81,13 +81,13 @@ href属性里面的内容是他的链接,title属性里面的内容则是他
|
||||
>
|
||||
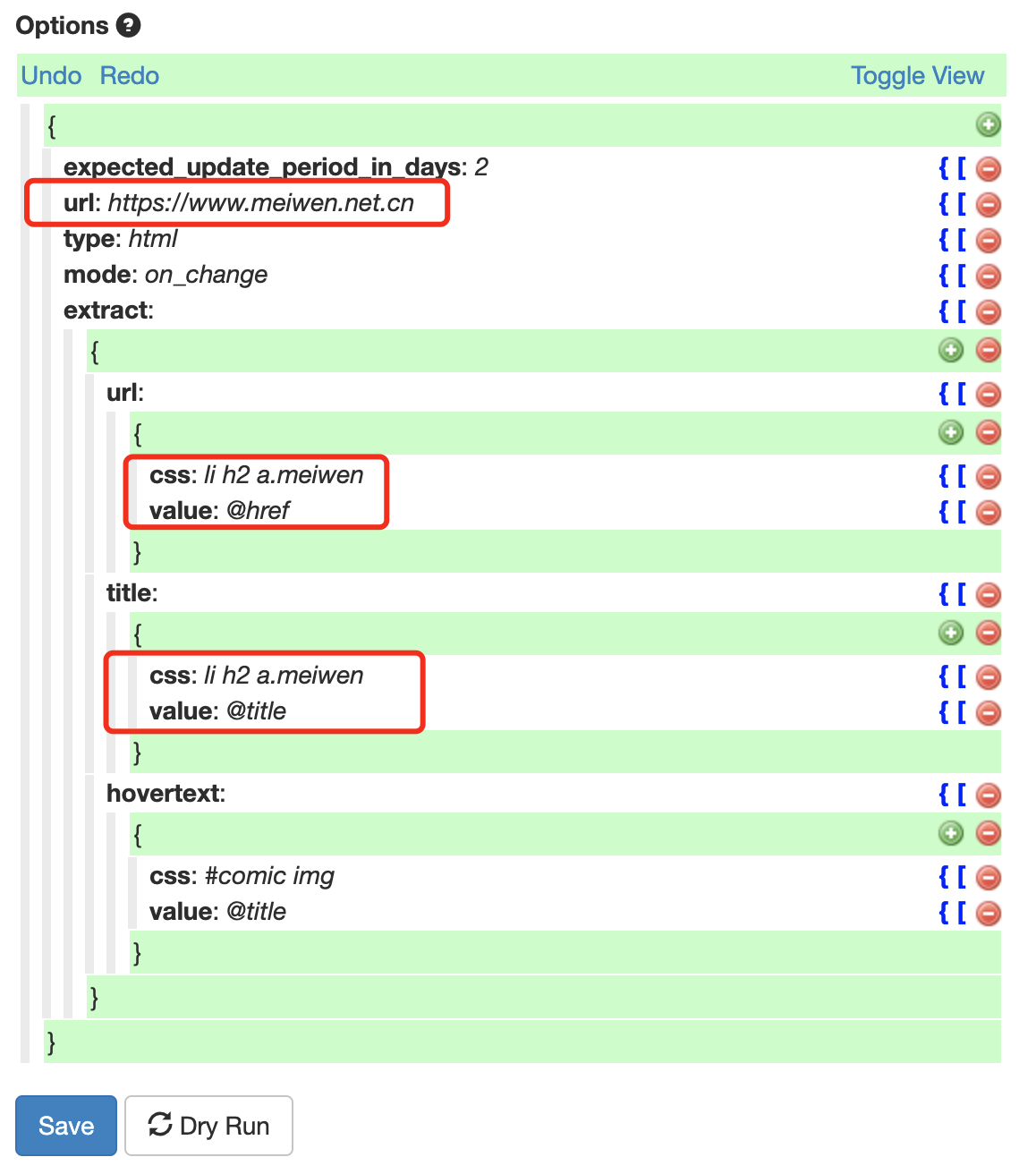
> 字符串处理函数和标签属性值变量可以一起使用,如`normalize-space(@title)`可以获取该标签的title属性值并删除多余的空白字符
|
||||
|
||||

|
||||
|
||||
|
||||
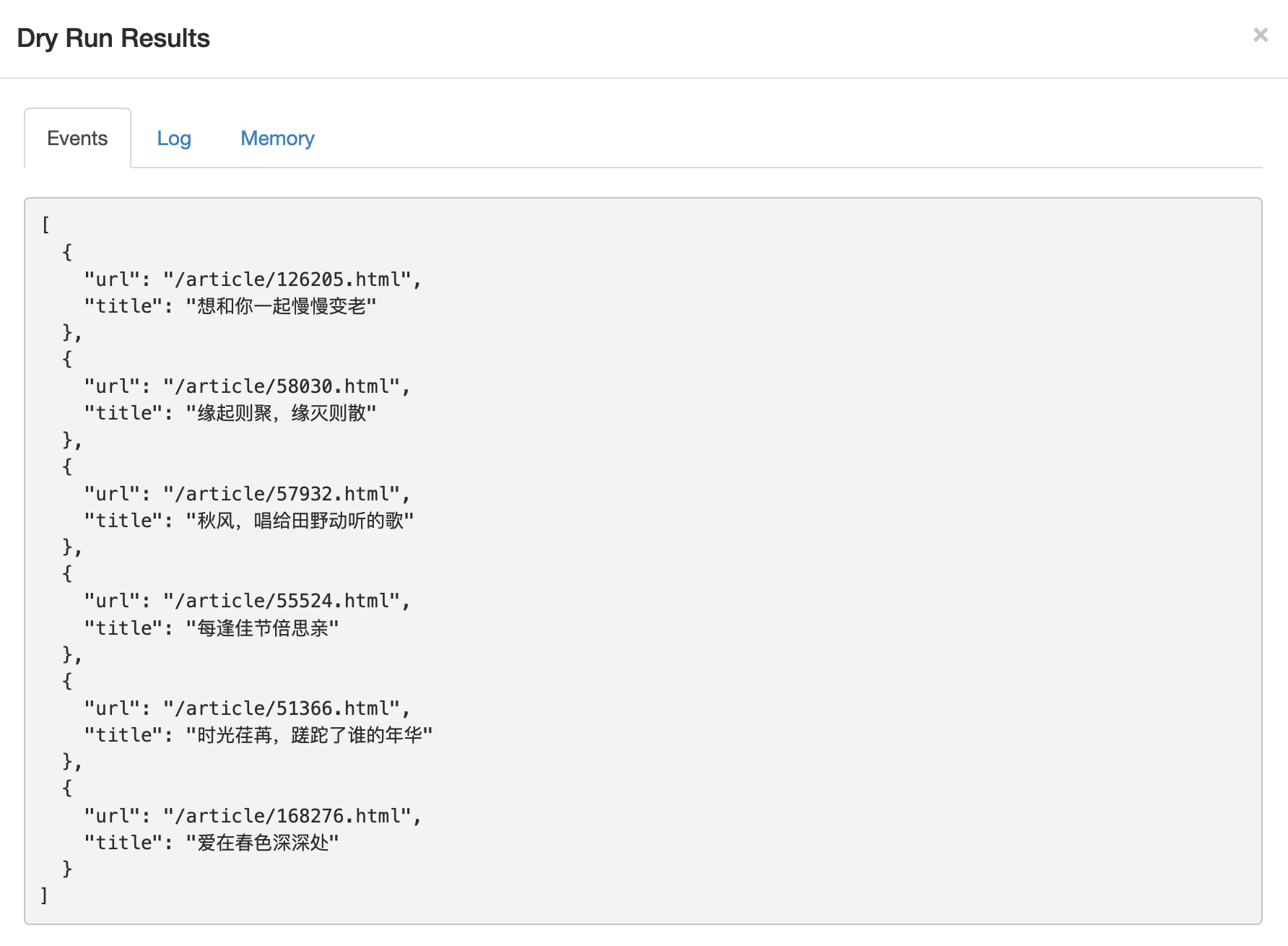
接下来点击Dry Run按钮进行测试,不出意外我们会得到一个json的输出,里面包括我们爬取到的每一项他的url和title。
|
||||
|
||||
如果没有成功,你可能需要删掉上面没有使用到的hovertext节点,因为该项指定的内容在我们刚才的网页中并不存在。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -97,27 +97,27 @@ href属性里面的内容是他的链接,title属性里面的内容则是他
|
||||
>
|
||||
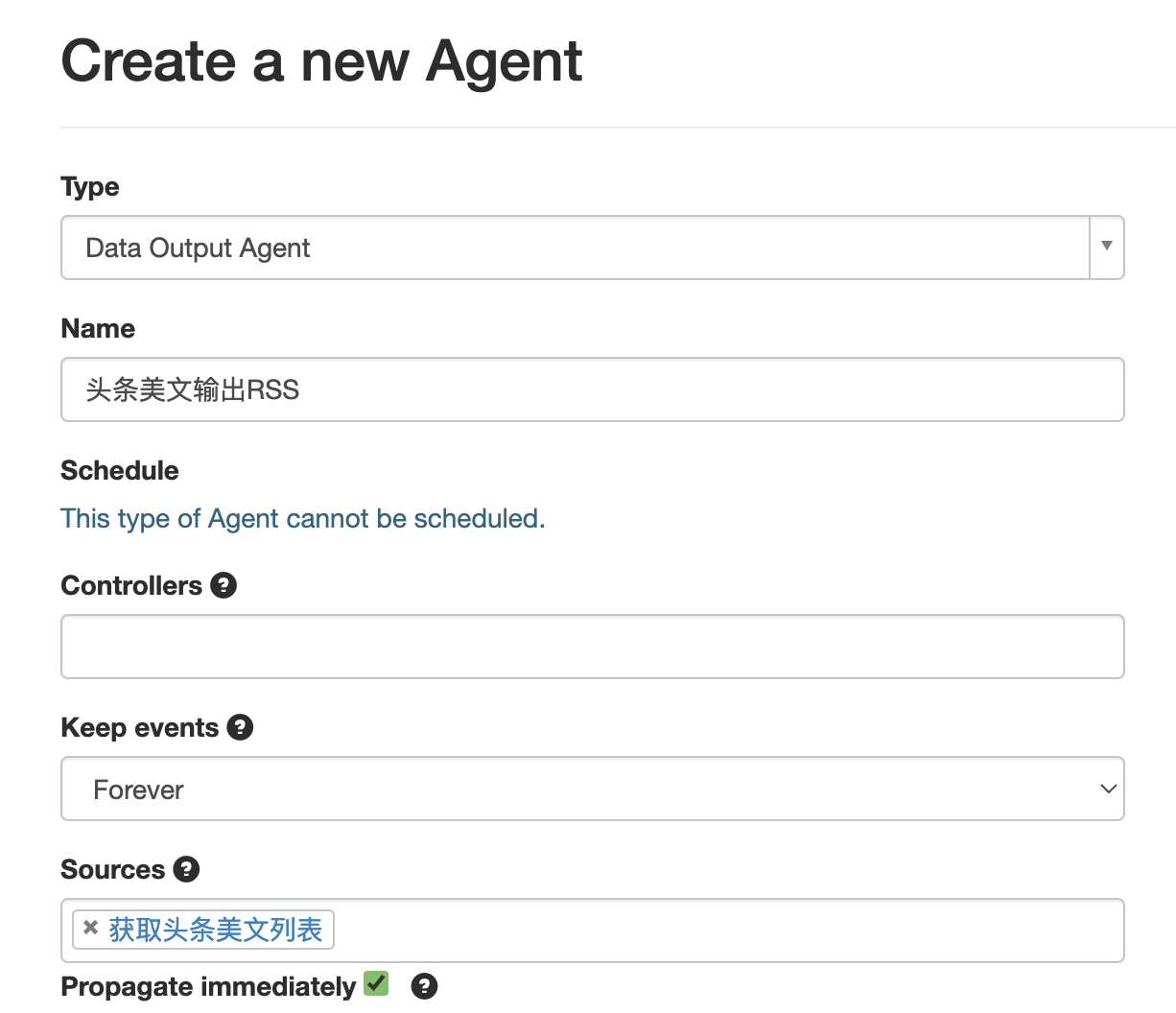
> The Data Output Agent outputs received events as either RSS or JSON. Use it to output a public or private stream of Huginn data.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
**Propagate immediately**是指即时处理来自Source Agent的Event,启用他方便我们调试,但会略微增加服务器负载,你可以自行决定是否使用。
|
||||
|
||||

|
||||

|
||||
|
||||
在secret字段中为你的这个RSS标注一个英文的名字,修改title字段标注你的RSS的名字。item字段是每条文章会有的属性,一般来说主要就title和link,分别设置为上文我们提取的值的变量名。这里添加一个guid字段,这是一篇文章的唯一标识符,避免RSS阅读器读到的文章标题不同但是内容相同,常见于某篇文章的标题被修改,这会导致RSS阅读器内出现多篇重复文章。
|
||||
|
||||
此外建议增加一个link字段,值设置为与爬取的网站的主域名一致,避免网站内使用相对链接开头的资源无法正常加载。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
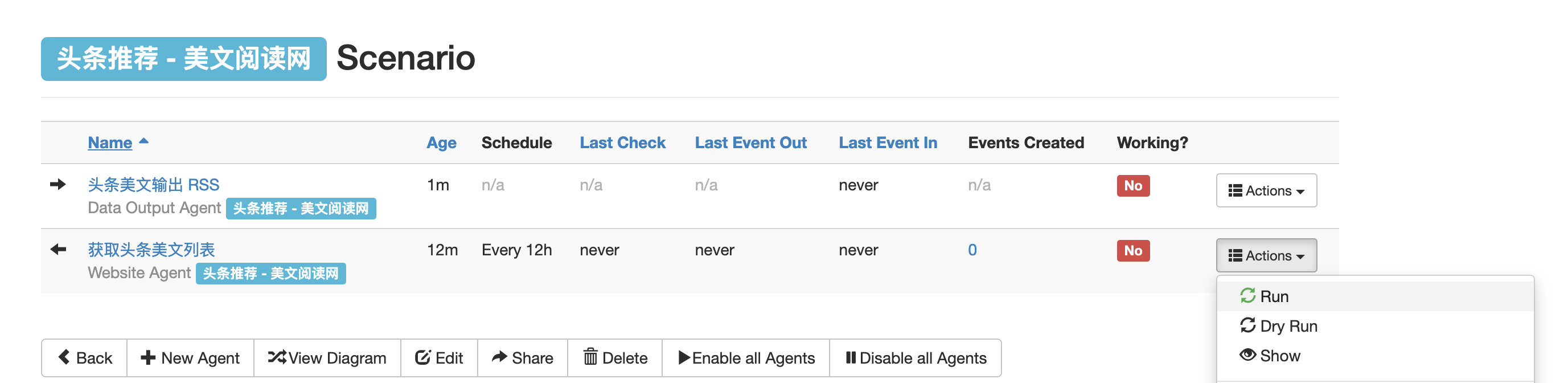
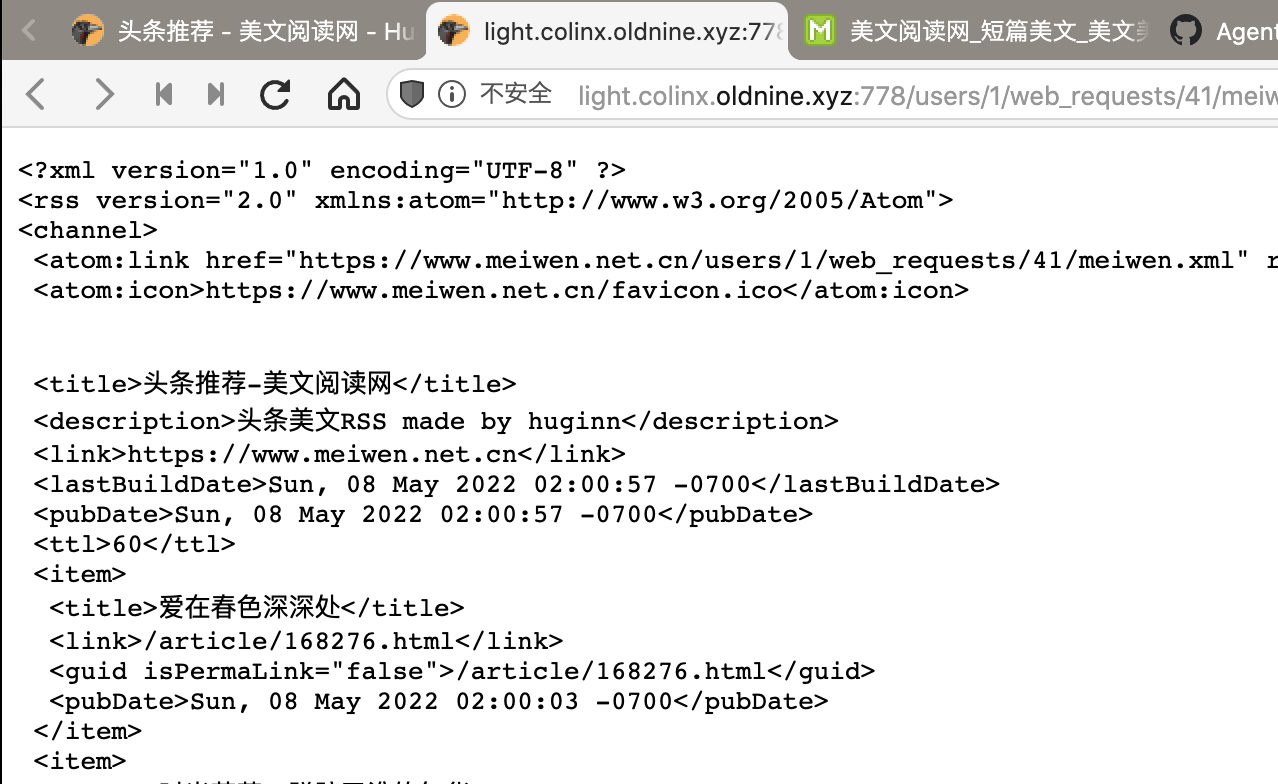
点击Save保存,回到Scenario界面,第一次需要手动点击运行一下刚才的Website Agent。稍等片刻后台会进行爬取,右上角会显示产生了多少个Event。再点开刚才设置的Data Output Agent查看详情,vola!右侧就会显示生成的RSS链接了,复制以xml结尾的链接到RSS阅读器中就可以订阅啦🎉
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -147,7 +147,7 @@ href属性里面的内容是他的链接,title属性里面的内容则是他
|
||||
|
||||
接下来以[这个网站](https://pccz.court.gov.cn/pcajxxw/pcgg/ggdh?lx=0)为例介绍一下,这个列表页的内容是由JavaScript动态生成的
|
||||
|
||||

|
||||
|
||||
|
||||
按照以下内容设置你的Post Agent
|
||||
|
||||
@@ -174,7 +174,7 @@ href属性里面的内容是他的链接,title属性里面的内容则是他
|
||||
|
||||
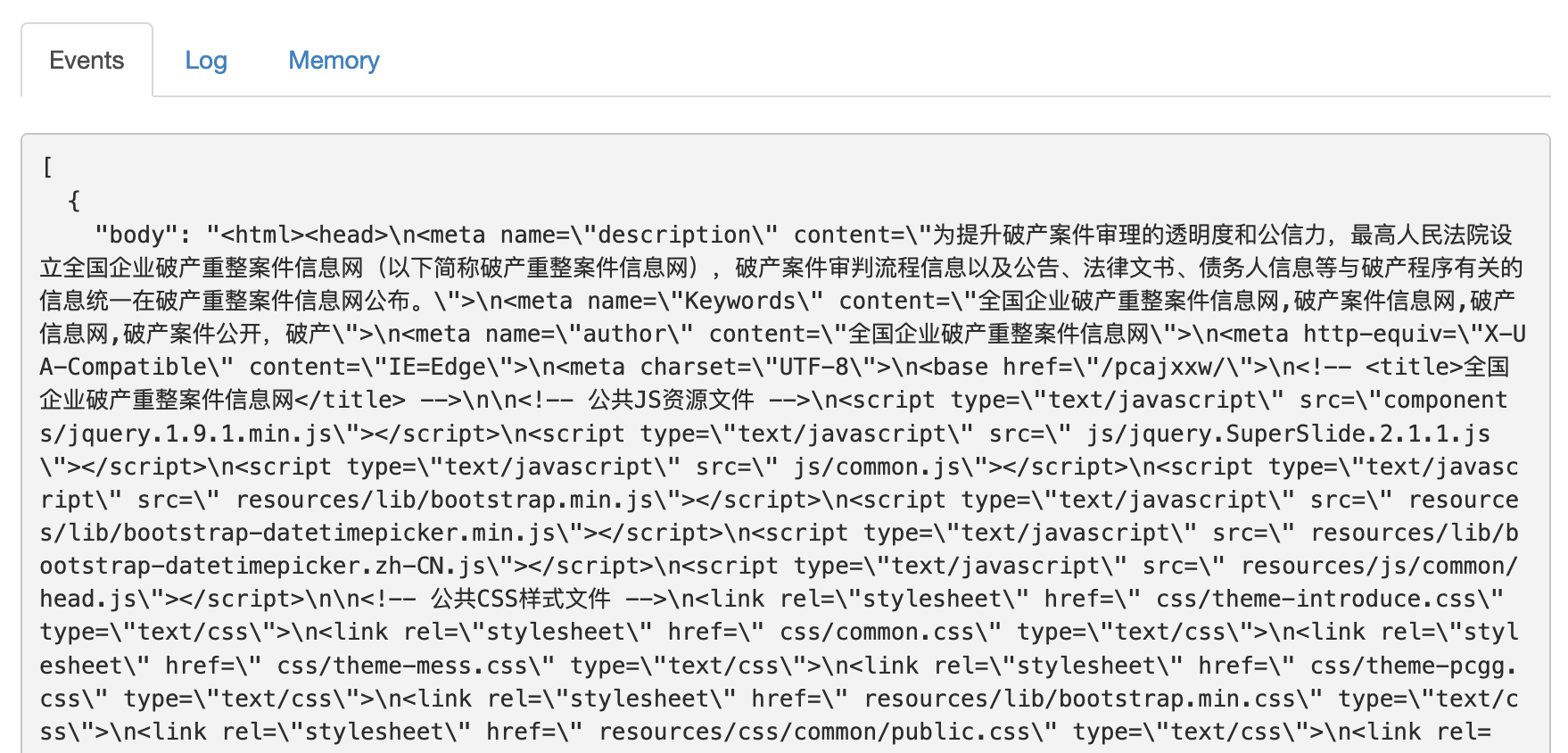
点击Dry Run,如果能返回一个带有`body`字段且里面有文本内容说明调用成功
|
||||
|
||||

|
||||
|
||||
|
||||
接下来点击Save保存,再新建一个Website Agent,Source设置为刚才的Post Agent。
|
||||
|
||||
@@ -205,7 +205,7 @@ href属性里面的内容是他的链接,title属性里面的内容则是他
|
||||
|
||||
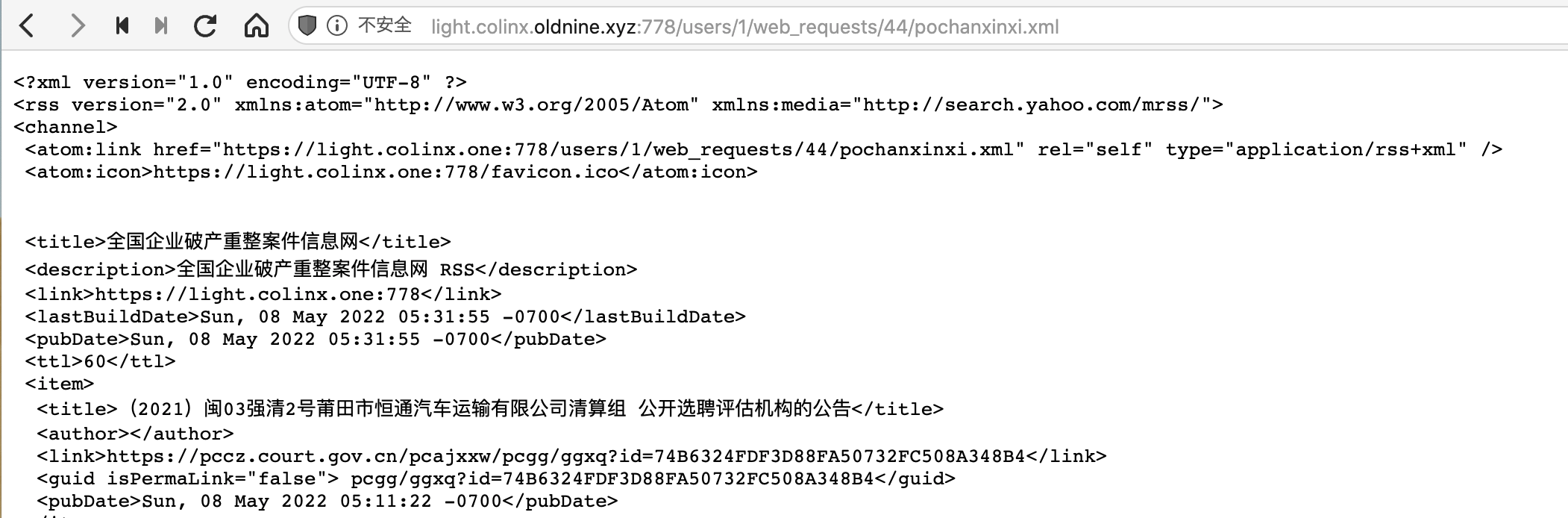
注意修改`data_from_event`的值,其他地方与爬取普通网站一样。再新建并配置一下Output Agent,RSS的链接就出来了
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -249,7 +249,7 @@ Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like
|
||||
|
||||
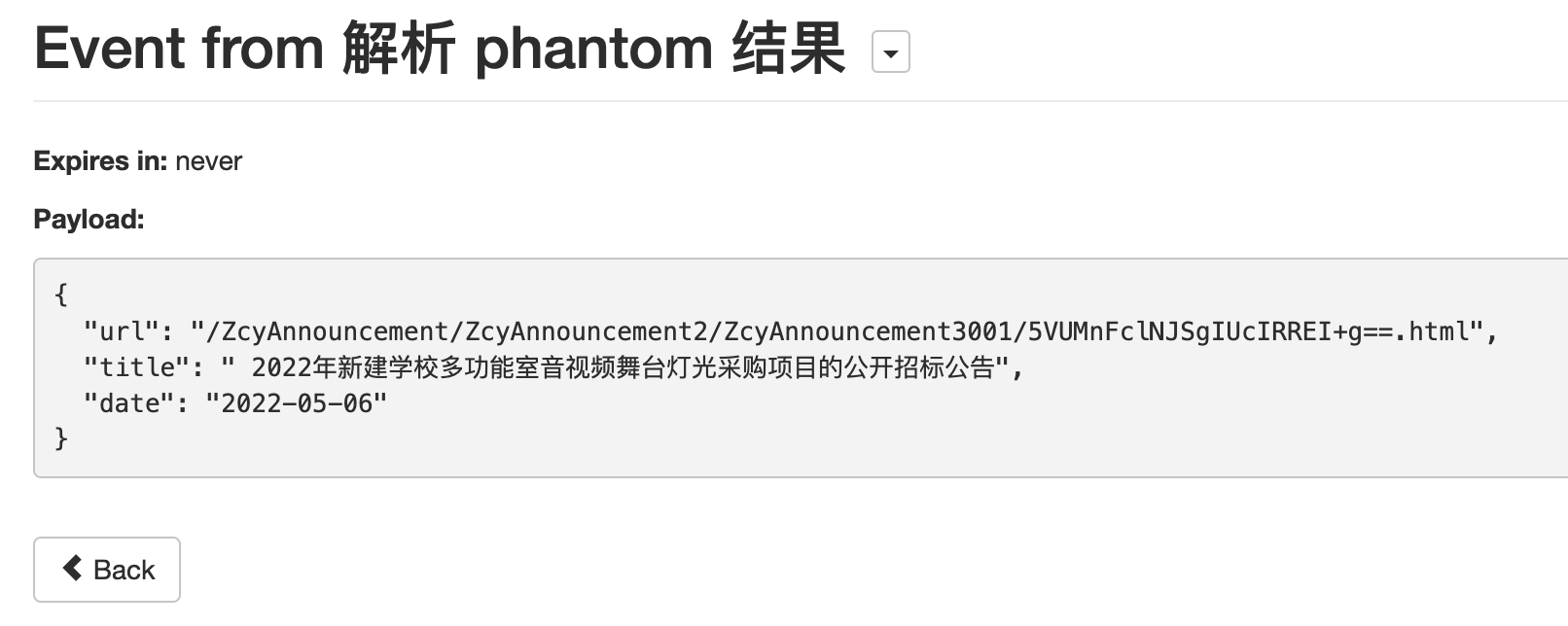
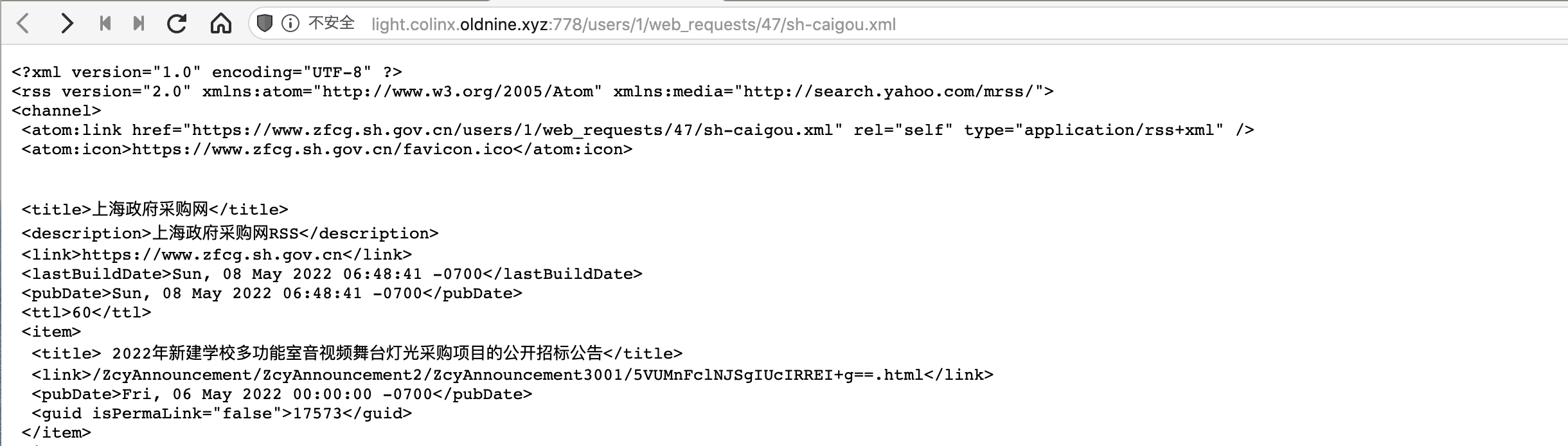
注意将原来的`url:??`的部分更改为`"url_from_event": "{{url}}"`,这样就指定使用Phantom JS Cloud为我们获取的完整网页,接下来的操作就大同小异了。配置好要爬取的字段和规则后点击Dry Run就可以看到结果
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -273,7 +273,7 @@ Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ tags:
|
||||
|
||||
这里安利一个油猴脚本:[豆瓣资源下载大师](https://greasyfork.org/zh-CN/scripts/329484-%E8%B1%86%E7%93%A3%E8%B5%84%E6%BA%90%E4%B8%8B%E8%BD%BD%E5%A4%A7%E5%B8%88-1%E7%A7%92%E6%90%9E%E5%AE%9A%E8%B1%86%E7%93%A3%E7%94%B5%E5%BD%B1-%E9%9F%B3%E4%B9%90-%E5%9B%BE%E4%B9%A6%E4%B8%8B%E8%BD%BD),可以在豆瓣的影视详情页右侧显示有资源的站点,非常方便
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
@@ -79,13 +79,13 @@ Golang编写的一个视频下载工具,同样支持国内站点
|
||||
|
||||
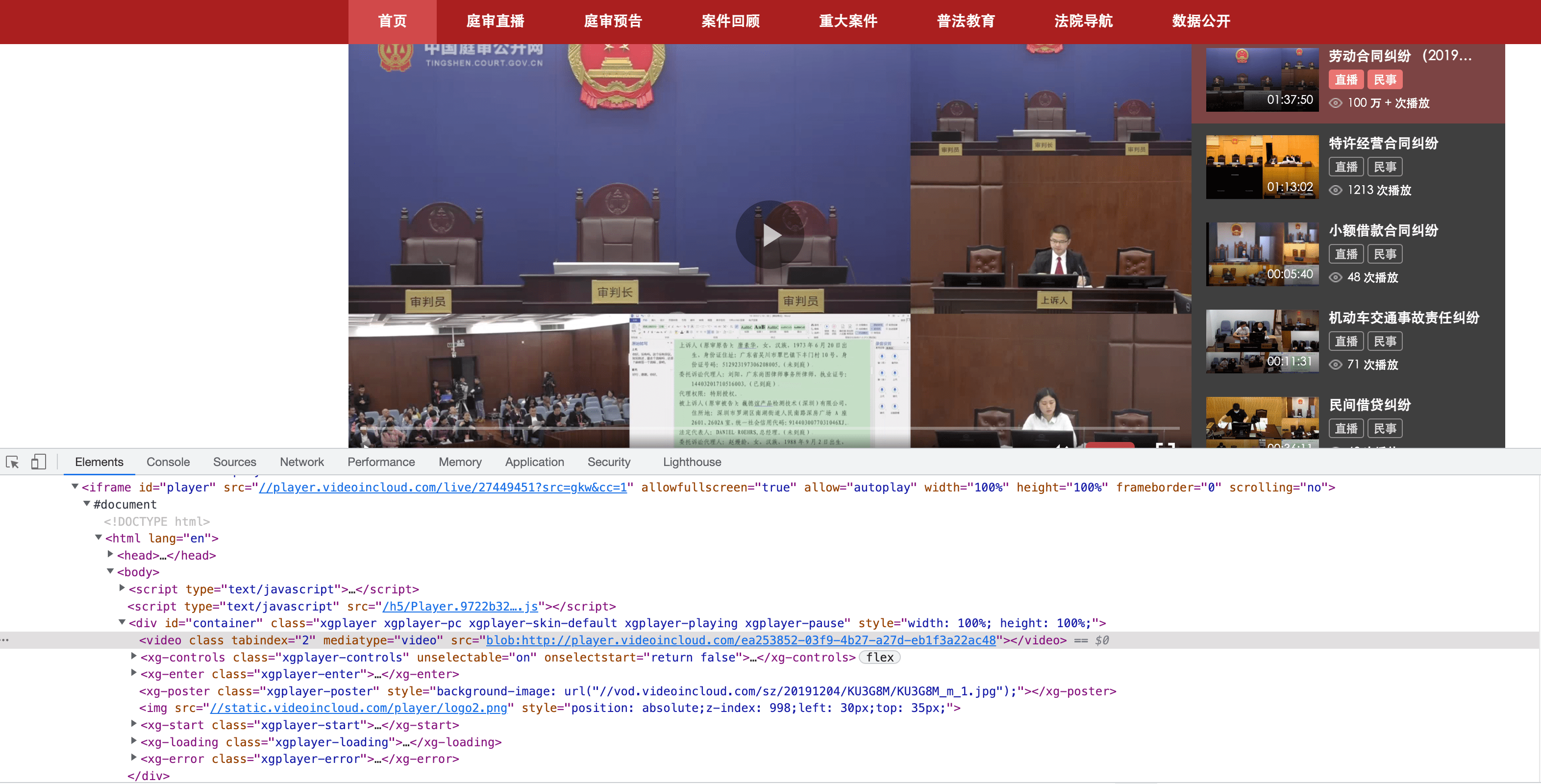
以中国庭审网的庭审录像视频为例,打开开发者工具定位到视频的部分发现video标签里面的url很奇怪,访问该链接也并不能访问到有效的视频。这种网页一般都是通过m3u8来下发分片文件的信息
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
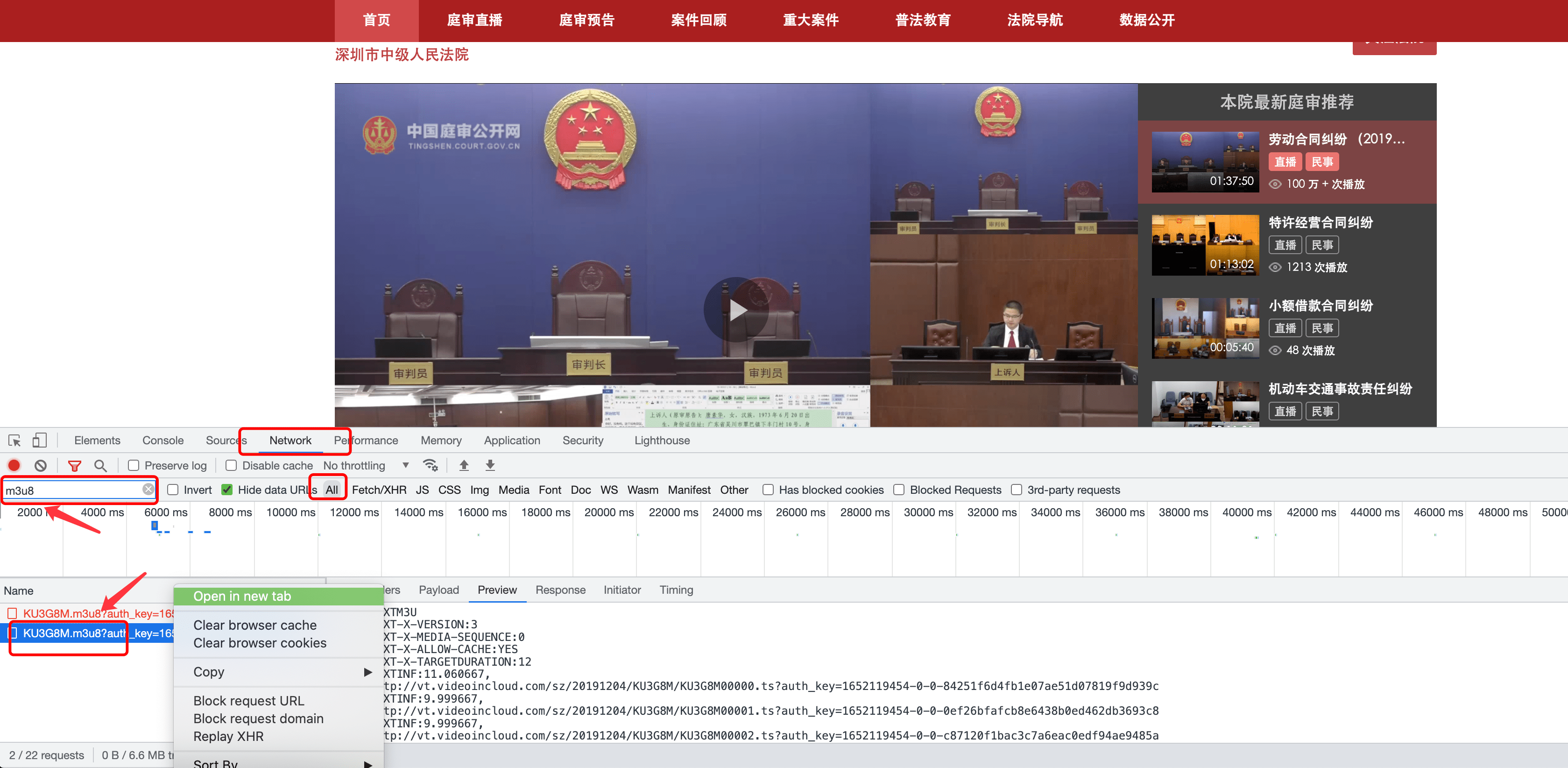
打开开发者工具的网络选项卡,监听网络活动,点击播放视频,会多出来很多条目分别代表每一个网络请求。在搜索框输入m3u8来进行过滤。定位到该请求后可以在新标签页打开,保存这个m3u8文件。
|
||||
|
||||

|
||||
|
||||
|
||||
之后我们可以利用ffmpeg载入这个m3u8文件并进行合并,如有需要可一并进行转码操作
|
||||
|
||||
@@ -121,7 +121,7 @@ ffmpeg -i xxxx.mp4 -vn -codec copy xxxx.aac
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user